
The Digital Circuits and Systems Group of ETH Zürich has been working on open-source hardware since 2013 under the PULP platform banner (https://pulp-platform.org/). As a founding member of the RISC-V foundation, ETH Zürich has designed some of the most commonly used RISC-V processor cores, such as CVA6/Ariane, CV32E40P/RI5CY, and Ibex/ZeroRiscy. ETH Zürich also has significant experience in ASIC design, having implemented over 50 ASICs manufactured using PULP-based open-source HW (http://asic.ethz.ch/). ETH Zürich is excited to bring this experience to the ISOLDE project and work with partners on establishing high-performance RISC-V-based computing systems that can be used in industrial quality products.
Our world has an endless appetite for additional computing power that triggers the digital revolution. At the same time, the raw electrical power needed for computing has reached levels that can not sustain this growth rate anymore. Simply put, the world needs more efficient ways of performing computing, doing more of it while spending less energy to do so.
Classical (von Neumann) computers have not changed much since their inception, and in very simplified terms, computer programs fetch simple instructions from memory that tell them what to do and then go fetch operands from memory, perform the operation, and then copy the result back to memory.
One of the ways to improve the efficiency of computing is to reduce the effort to perform this part of the operation. In regular (scalar) processing, the instruction tells the processor what to do with one word of data (usually 64 bits). So, if an array of data is being processed (with, for example, 1000 elements), the processor repeats the same task for all the elements in the array. Vector processing tries to take advantage of this and specifies operations on large vectors. A simple vector instruction can be used to schedule 1000 additions instead of executing 1000 individual additions separately. As long as you have many such operations, you can perform them more efficiently.
To this extent, the RISC-V ISA defines the RISC-V Vector extension (RVV), a set of instructions to perform vector operations (https://github.com/riscv/riscv-v-spec/blob/master/v-spec.adoc), and ETH Zürich has been investigating different approaches on how to a) implement such vector engines and b) pair them with existing processors to extend their capabilities.
The Ara design started when the RVV specification was still in its early stages and has been designed to work in tandem with the CVA6/Ariane core. Versions of this openly available core have already been taped out, as can be seen in Figure 1.
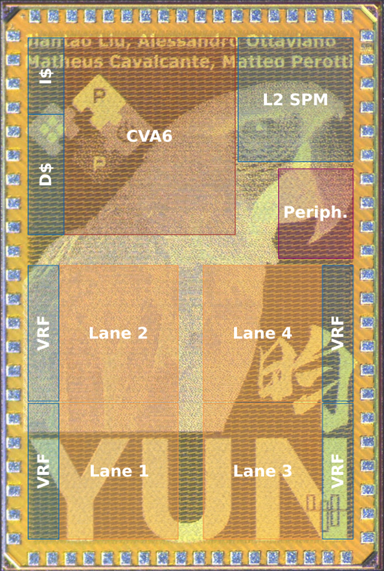
Figure 1 - Die shot of the Yun chip. Highlighted: CVA6, the scalar processor with its level-1 cache memories, and Ara’s four vector lanes with their Vector Register File (VRF) chunks. In the upper-right corner: peripherals and main level-2 scratchpad (SP) memory.
Ara was designed to efficiently accelerate the computation of long vectors and showed the potential of RVV by reaching almost peak performance on ubiquitous kernels such as matrix multiplications and convolutions, which are largely used in machine learning tasks. Figure 2 shows the power breakdown of combined CVA6/Ara executing a large matrix multiplication that can take advantage of the vector extensions.
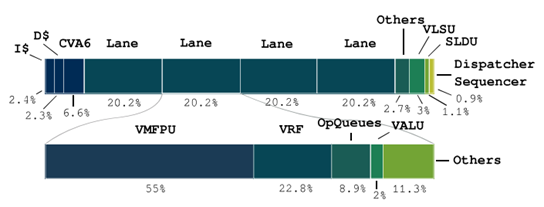
Figure 2 - Ara Power consumption breakdown during a matrix multiplication. Most of the power is spent in the vector floating-point unit (VMFPU), which is where the core computation is done. The vector architecture helps keep the power related to the fetch of the instruction low, as testified by the small 2.4% of the budget taken by CVA6’s instruction cache.
A second approach the group has taken is to explore how the vector processor architecture maps to the embedded world by developing a tiny and efficient integer-only 32-bit vector accelerator named Spatz (Figure 3) that can be integrated into the Mempool many-core system. Spatz, as opposed to Ara, was coupled with a tiny and agile scalar processor called Snitch and further showed the potential of RVV in a more constrained processing domain.
Since the first Ara prototype, ETH Zurich has explored different ways of coupling vector accelerators to scalar processors, and many different interfaces were changed over time, with a particular interest toward the OpenHW Group’s X-interface, already used with an early design of Spatz. Currently, the open-source Ara is being actively developed following the last development of the specifications.
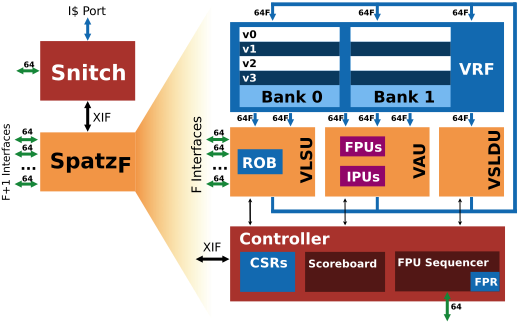
Figure 3 - Spatz architecture. Spatz works in tandem with the Snitch processor by means of the X-interface.
As mentioned before, processors usually operate at a fixed size of words (usually 64-bit), which means that any value that is computed is represented by 8 bytes in memory. There are some applications where the range of numbers that are used in computing is quite limited (for example, 0-100), and the same amount of memory can be used to represent multiple different numbers, significantly reducing the memory needs and the computation complexity, with a reduction of the overall energy needed to perform these operations.
To be effective and efficient, a computing system needs to handle different types of number representations. These multi-precision computing blocks allow computing to take place in the most efficient number representation while allowing the full range of capabilities to remain intact.
ETH Zürich has been actively working on exploring efficient arithmetic computing units that can support multiple number formats, mainly through the fpnew, a RISC-V-compliant Floating-Point Unit (FPU) originally developed with multi-precision capabilities as one of its fundamental goals and now maintained by OpenHW Group under the name cvfpu. Its modular multi-precision-ready design allows for computing floating-point operations from 64-bit to 8-bit floating-point data. It also supports alternative formats for 16 and 8 bits, more and more used in the machine learning domain.
Vector processing and multi-precision capabilities are fundamental steps toward fast and efficient processing in an era in which focusing the power where it is really needed, without any waste, is paramount. To this extent, ETH Zurich is working on fully supporting the cvfpu multi-precision capabilities on the Ara vector processor to unleash even higher energy efficiency during the computation.
In ISOLDE, we aim to apply this know-how to multi-precision Vector processing units paired with RISC-V cores to improve the efficiency of the target use cases and provide Europe and the whole open-source community at large with new tools to tackle the upcoming computational challenges.

![]()
![]()
![]()